Appearance
《左手mongoDB 右手Redis》的45个实例
01使用python实现队列
python
import time
import random
from queue import Queue
from threading import Thread
#生产者
class Producer(Thread):
def __init_(self, queue):
super().__init__()
self.queue = queue
def run(self):
while True:
a = random.randint(0,10)
b = random.randint(90,100)
print(f'生产者生产了两个数字: {a},{b}')
self.queue.put((a,b)) # 把两个数字用元组的形式放进队列中
time.sleep(2)
# 消费者
class Consumer(Thread):
def __init_(self, queue):
super().__init__()
self.queue = queue
def run(self):
while True:
# block=True表示 如果队列为空则阻塞在这里,直到队列有数据位置
num_tuple = self.queue.get(block=True)
sum_a_b = sum(num_tuple)
print(f'消费者消费了一组数,{num_tuple[0]}+{num_tuple[1]}={sum_a_b}')
# 随机时间暂停
time.sleep(random.randint(0,10))
# 运行代码
queue = Queue()
# 启动子线程
producer = Producer(queue)
consumer = Consumer(queue)
producer.start()
consumer.start()
# 时间暂停 不会立即结束
while True:
time.sleep(1)
代码实现原理
使用Python自带的queue对象来实现队列: (1)使用Python实现一个简单的“生产者/消费者”模型。 (2)使用Python的queue对象做信息队列。 在Python使用多线程实现生产者与消费者的程序中,可以使用Python自带的queue对象来作为生产者与消费者沟通的队列。
代码作用:
生产者负责产生两个数字,消费者负责把两个数字相加。
代码缺点:
但是,由于消费者暂停时间是随机的,我们不能提前知道它每次会暂停多久。
如果使用Python自带的队列,就会出现以上的疑问。
因为开发者不能直接看到队列的长度。如果开发者一开始就考虑到“需要随时观察队列长度”这个需求,那么可以通过对代码做一些修改来实现。但如果一开始没有打算观察队列长度,仅仅是临时起意,那该怎么办?
如果不仅想看队列长度,还想看里面每一组数都是什么,又该如何操作?
假设队列里已经堆积了一百组数,现在想增加消费者,该怎么增加?
如再运行一个Python程序,那能去读第一个正在运行中的Python程序中的队列吗?
Python 把队列中的数据存放在内存中。如果电脑突然断电,那队列里的数是不是全都丢失了? 为了防止丢数据,是否需要把数据持久化到硬盘?那持久化的代码怎么写,代码量有多少,考不考虑并发和读写冲突?
02.使用Redis替代Queue
python
import time
import json
import redis
import random
form threading import Thread
class Producer(Thread):
def __init__(self):
super().__init__()
self.queue = redis.Redis()
def run(self):
while True:
a = random.randint(0,10)
b = random.randint(90,100)
print(f'生产者生产了两个数字: {a},{b}')
self.queue.rpush('producer',json.dumps((a,b)) # 把两个数字用元组的形式放进队列中
time.sleep(2)
# 消费者
class Consumer(Thread):
def __init_(self):
super().__init__()
self.queue = redis.Redis()
def run(self):
while True:
# block=True表示 如果队列为空则阻塞在这里,直到队列有数据位置
num_tuple = self.queue.blpop('producer')
a,b = json.loads(num_tuple[1].decode())
print(f'消费者消费了一组数,{a}+{b}={a+b}')
# 随机时间暂停
time.sleep(random.randint(0,10))
producer = Producer()
producer.start()
consumer = Consumer()
consumer.start()
while True:
time.sleep(1)
代码实现原理:
redis的api
代码作用:
现在,生产者和消费者可以放在不同的机器上运行,想运行多少个消费者就运行多少个消费者,想什么时候增加消费者都没有问题。 如果想观察当前队列里有多少数据,或者想看看具体有哪些数据在队列里,则在redis的cli中执行一条命令:“llen 队列名称”即可。
代码优点:
用redis弥补了用python定义数据结构队列的不足
03.Mongodb: 创建数据库与集合写入数据
shell
# example_data_1 为集合名称
# 查询所有
db.getCollection('example_data_1').find({})
# 插入单条数据
db.getCollection('example_data_1').insertOne({"name": " 张小二 ", "age": 17,"address": "浙江"})
db.getCollection('example_data_1').insertOne({'name': ’王小六’, 'age': 25, 'work': ’厨师’})
# 批量插入
data_list = [
{'name':'张小二','age':20,'address':'北京'},
{'name':'张大二','age':21,'address':'南京'},
{'name':'张老二','age':22,'address':'东京'},
{'name':'张中二','age':23,'address':'西京'},
]
db.getCollection('example_data_1').insertMany(data_list)
代码作用:
mongodb
1.查询所有
2.插入单条数据
3.插入多条数据
04.Mongodb: 查询数据
python
# 1.查询固定值数据
# 1.1查询所有数据
db.getCollection('example_data_1').find({})
# 1.2查询特定数据
#db.getCollection('example_data_1').find({'字段1':'值1','字段2':'值2'})
db.getCollection('example_data_1').find({'age':20})
# 2.查询范围值数据
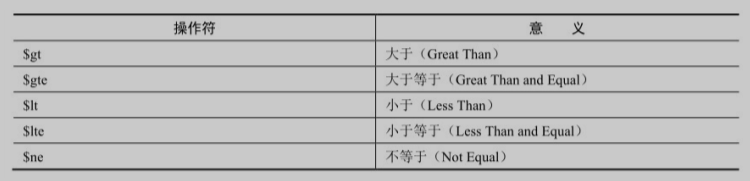
# db.getCollection('example_data_1').find({'age':{'操作符1':'边界1','操作符2':'边界2'}})
# 大于等于操作符“$gte”
db.getCollection('example_data_1').find({'age': {'$gte': 25}})
# 查询所有“age”大于21并小于等于24的数据
db.getCollection('example_data_1').find({'age': {'$lt': 25, '$gt': 21}})
# 查询所有“age”大于21并小于等于24的数据,且“name”不为“夏侯小七”的记录
db.getCollection('example_data_1').find({
'age': {
'$lt': 25, '$gt': 21
},
'name': {'$ne':'夏侯小七'}
})
# 3.限定返回那些字段
# db.getCollection('example_data_1').find(用于过滤记录的字段,用于过滤限定字段的字典)
# 如果值为0,则表示在全部字段中剔除值为0的这些字段并返回。
# 如果值为1,则表示只返回值为1的这些字段
# 则限定字段的字典里面的值只可能全都是0或全都是1,不可能1和0混用,一旦混用则MongoDB就会报错。
# 查询数据集example_data_1,但不返回“address”和“age”字段。
db.getCollection('example_data_1').find({}, {'address': 0, 'age': 0})
# 要求只返回name字段和age字段
db.getCollection('example_data_1').find({}, {'name': 1, 'age': 1})
# 4.修饰返回结果
#(1)满足要求的数据有多少条——count()命令。
db.getCollection('example_data_1').find({'age': {'$gt': 21}}).count()
#(2)限定返回结果——“limit()”命令。
# db.getCollection('example_data_1').find().limit(限制返回条数)
# 对于数据集example_data_1,限制只返回4条数据。
db.getCollection('example_data_1').find().limit(4)
#(3)对查询结果进行排序——“sort()”命令。
#其中,字段的值为-1表示倒序,为1表示正序。
# 对所有“age”大于21的数据,按“age”进行倒序排列。
db.getCollection('example_data_1').find({'age': {'$gt': 21}}).sort({'age': -1})
05.Mongodb: 修改数据
python
修改这两个命令只有以下区别
● updateOne:只更新第1条满足要求的数据。
● updateMany:更新所有满足要求的数据。
# 数据集 example_data_1,“name”为“王小六”的这个记录是没有“address”字段的。现在需要为它增加这个字段,同时把“work”从“厨师”改为“工程师”。
db.getCollection('example_data_1').updateMany(
{'name':'王小六'},
{'$set': {'address': '苏州','work': '工程师'}}
)
06.Mongodb: 删除数据
python
要从数据集example_data_1中删除字段“hello”值为“world”的这一条记录。
(1)从集合中删除单条数据。
(2)从集合中批量删除多条数据。
只要会查询数据,就会删除数据。为了防止误删数据,一般的做法是先查询要删除的数据,然后再将查出的数据删除。
(1)查询字段“hello”中值为“world”的这一条记录
db.getCollection('example_data_1').find({'hello': 'world'})
(2)把查询语句的“find”修改为“deleteOne”(如果只删除第1条满足要求的数据),或把查询语句的“find”修改为“deleteMany”(如果要删除所有满足要求的数据)。
具体命令如下:
db.getCollection('example_data_1').deleteMany({'hello': 'world'})
(3)在返回的数据中,“acknowledged”为“true”表示删除成功,“deletedCount”表示一共删除了1条数据。
(4)再次查询example_data_1,发现已经找不到被删除的数据了
提示:
慎用删除功能。一般工程上会使用“假删除”,即:在文档里面增加一个字段“deleted”,如果值为0则表示没有删除,如果值为1则表示已经被删除了。默认情况下,deleted字段的值都是0,如需要执行删除操作,则把这个字段的值更新为1。而查询数据时,只查询deleted为0的数据。这样就实现了和删除一样的效果,即使误操作了也可以轻易恢复。
07.Mongodb: 数据去重
python
在数据集example_data_1中,进行以下两个去重操作。
(1)对“age”字段去重。
(2)查询所有“age”大于等于24的数据,再对“age”进行去重。
db.getCollection('example_data_1').distinct(’字段名’, 查询语句的第一个字典)
distinct()可以接收两个参数:
● 第1个参数为字段名,表示对哪一个字段进行去重。
● 第2个参数就是查询命令“find()”的第1个参数。distinct命令的第2个参数可以省略。
1.对“age”字段去重
对“age”字段去重的语句如下:
db.getCollection('example_data_1').distinct('age')
2.对满足特定条件的数据去重
首先查询所有“age”大于等于24的数据,然后对“age”进行去重。
db.getCollection('example_data_1').distinct('age', {'age': {'$gt': 24}})
08.python操作mongoDB
8.1安装pyMongo
python3 -m pip install pymongo
8.2 连接数据库
本章使用不设置密码、不改端口、本地运行的MongoDB。
运行再本地
python
from pymongo import MongoClient
client = MongoClient()
8.3连接库与集合
方式1:
python
from pymongo import MongoClient
client = MongoClient()
database = client.数据库名
collection = database.集合名
实践
from pymongo import MongoClient
client = MongoClient()
database = client.chapter_3
collection = database.example_data_1
方式2:
python
from pymongo import MongoClient
client = MongoClient()
database = client['chapter_3']
collection = database['example_data_1']
如果有多个数据库要测试可以吧数据库名与集合名抽离出来
python
from pymongo import MongoClient
# 数据库配置
db_name = 'chapter_3'
collection_name = 'example_data_1'
client = MongoClient()
database = client[db_name]
collection = database[collection_name]
8.4使用循环链接多个集合
python
from pymongo import MongoClient
client = MongoClient()
# 数据库配置
db_name_list = ['develop_env_alpha','develop_env_beta']
collection_name = 'example_data_1'
for each_db in db_name_list:
database = client[each_db]
collection = database[collection_name]
collection.updateMany(.....)
MongoDB的命令使用的是驼峰命名法,而PyMongo使用的是“小写字母加下划线”的方式

8.5python操作mongo数据库
8.5.1 批量插入
insert_many

8.5.2 查询
在Python中,从MongoDB中查询所有“age”大于21小于25,并且“name”不等于“夏侯小七”的记录。

8.5.3 更新
(1)对于“name”为“公孙小八”的记录,将“age”更新为80,将“address”更新为“美国”。
python
collection.update_many(
{'name':'公孙小八'},
{'$set': {'address':'美国','age':80}}
)
update_many有个缺陷 就是当python中没有这个记录的时候 会报错
所以需要加上 upsert参数
python
collection.update_many(
{'name':'公孙小六'},
{'$set': {'address':'世界','age':10,'name':'公孙小六'}},
upsert=True
)
如果打开了更新或插入功能,则“$set”的值是完整的文档内容,应该包含每一个字段,而不仅仅是需要被更新的字段,否则被插入的内容只有被更新的这几个字段。
8.5.4删除
删除“age”为0的数据。删除语句如下:
python
collection.delete_many({'age': 0})
8.5.5 mongodb与python不通过的操作
1.空值
mongoDB空值为null
python中空值为None
python
from pymongo import MongoClient
client = MongoClient()
# 数据库配置
db_name_list = 'develop_env_alpha'
collection_name = 'example_data_1'
database = client[each_db]
collection = database[collection_name]
rows = collection.find({'grade':None})
for row in rows:
print(row)
2.布尔值
在MongoDB中,“真”为true,“假”为false,首字母小写;
在Python中,“真”为True,“假”为False,首字母大写。
python
from pymongo import MongoClient
client = MongoClient()
# 数据库配置
db_name_list = 'develop_env_alpha'
collection_name = 'example_data_1'
database = client[each_db]
collection = database[collection_name]
rows = collection.find({'student':True})
for row in rows:
print(row)
##### 3.排序
在MongoDB中,sort()命令接收一个参数,这个参数是一个字典,Key是被排序的字段名,值为1或者−1。
在Python中,sort()方法接收两个参数:第1个参数为字段名,第2个参数为-1或者1。写成如图3-69所示样子就能够正常运行。
python
from pymongo import MongoClient
client = MongoClient()
# 数据库配置
db_name_list = 'develop_env_alpha'
collection_name = 'example_data_1'
database = client[each_db]
collection = database[collection_name]
rows = collection.find({},{'_id':0}).sort('age',-1) #不能写成sort({'age':-1})
for row in rows:
print(row)
4.查询_id
python
from bson import ObjectId
collection.find({'_id': ObjectId('5b2f75d26b78a61364d09f45')})
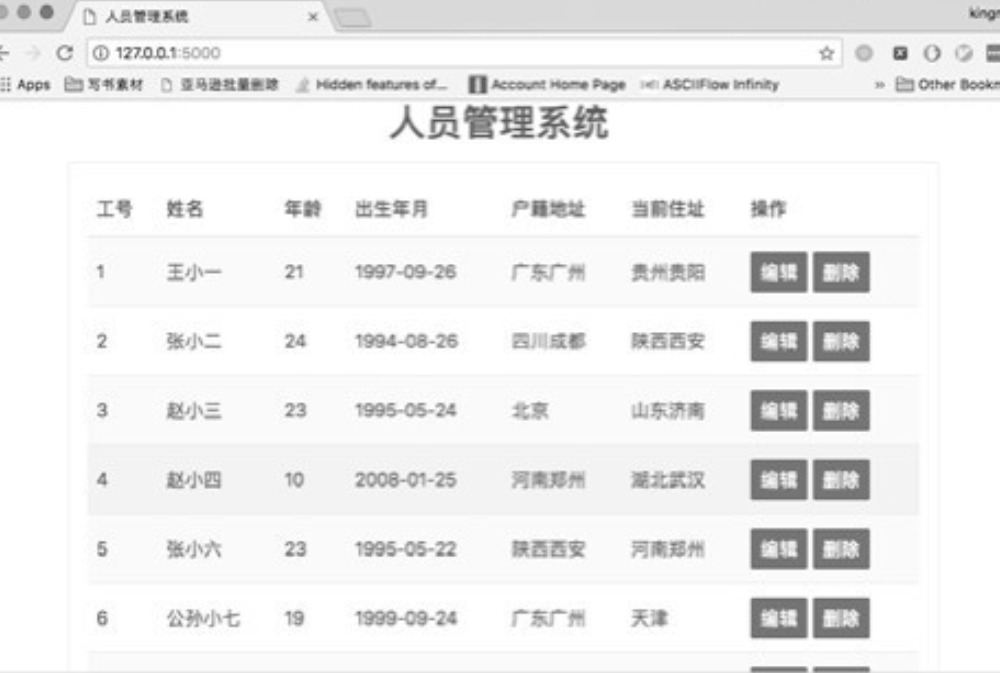
09.用mongodb开发员工信息管理系统
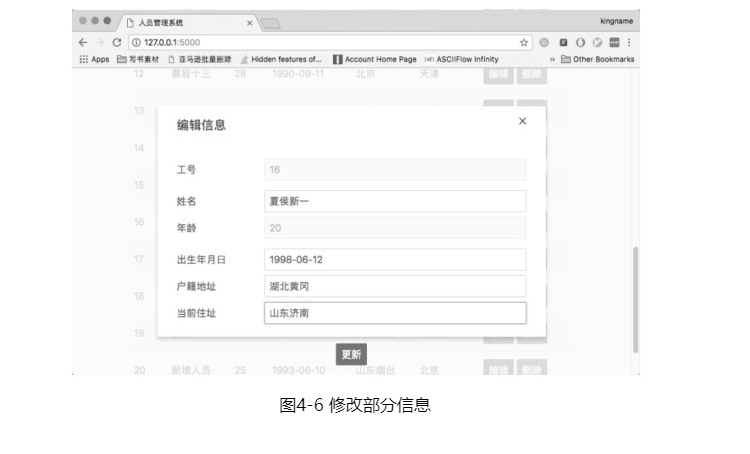
员工信息管理系统界面
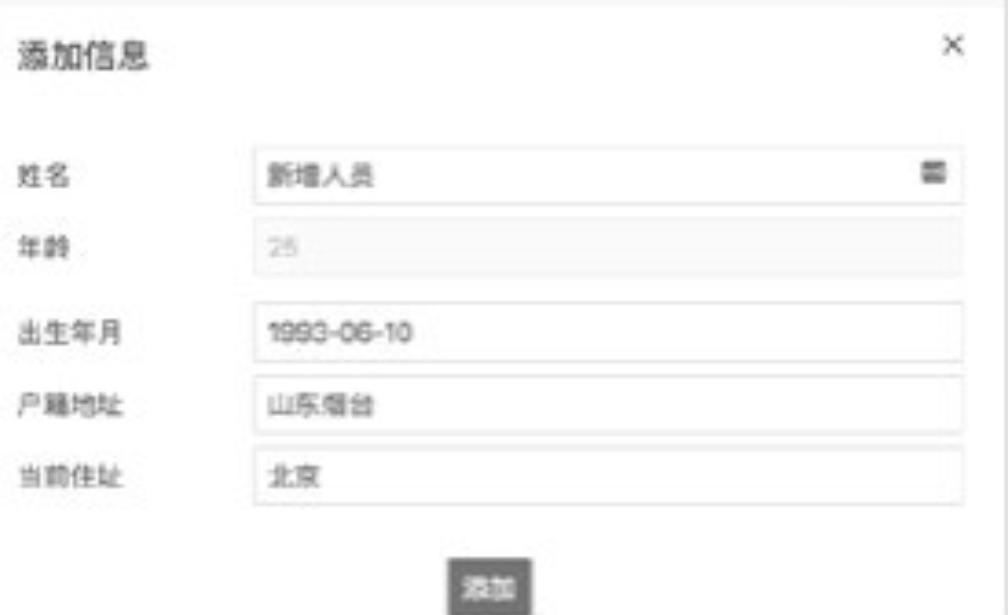
9.1 添加信息